The System and Nodes
The System is the collection of all the nodes within a single environment. This architecture diagram is an example of one Ocient System. Across systems, the number of nodes can vary along with the total storage capacity. Within a single system, users can define varying numbers of databases, storage groups, users, etc. An Ocient System is made up of a collection of distributed nodes which each play a predefined role in the data warehouse. The different roles are generally responsible for storing and analyzing data, administration, and moving data into Ocient. These nodes are connected to each other through a high-speed 100 Gbps network connection. In addition to storing user data, the data warehouse also stores metadata about the system and data for its own internal operation and recovery. This collection of nodes, their data, and the interconnection between them make up the Ocient System. The end user, analyzing data in Ocient, connects to this system through a JDBC or a -based client. From there, they interact with the database objects, such as tables and views. The architecture itself is abstracted from users, allowing them to focus on SQL queries and results. While the number of nodes in an environment might vary, the inclusion of and purpose of the different roles do not. The following sections briefly describe the components in the architecture.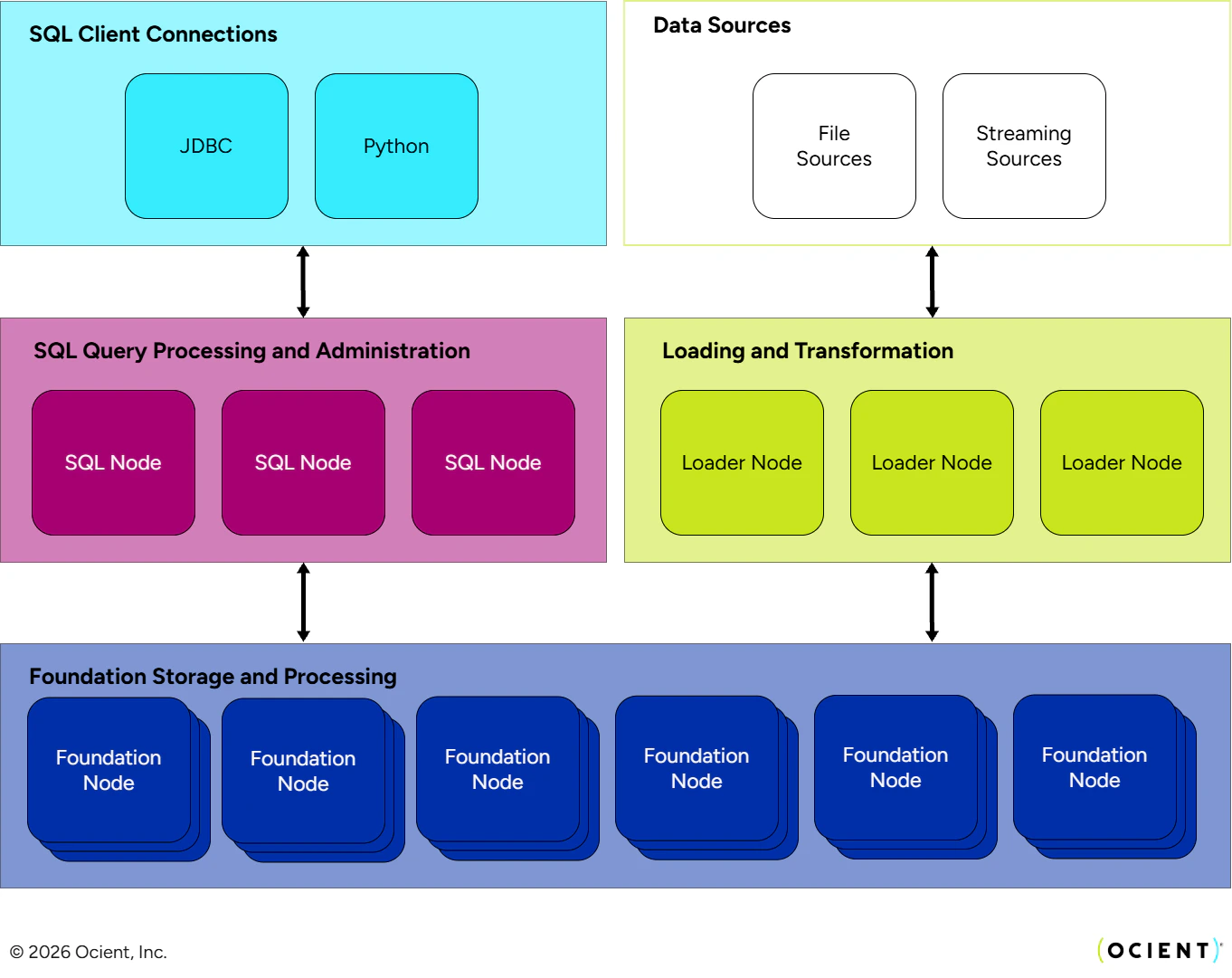
Node Types
SQL Nodes
A SQL Node is responsible for receiving incoming SQL requests and parsing the statements. This node also serves as the interface for System Administrators and Database Administrators to configure and maintain an Ocient System. Administrators can connect to a SQL Node using the Ocient command-line interface or their chosen client. When a SQL Node receives a query, it creates a plan for it using one of two optimization methods. After there is a plan for the query, the SQL Node distributes it to the Foundation Nodes. When the Foundation Nodes finish their processing, they return data back to the SQL Node for further processing and packaging the result set to the client. When the result set is finalized, the SQL Node returns the data to the client. Beyond the Foundation Nodes, further processing is done on the SQL Nodes to process intermediate result sets delivered by the Foundation Nodes. Depending on the query, the SQL Node is responsible for a different proportion of the overall work of the query. Common processing done here are aggregations and joins that happen across the intermediate results delivered by the Foundation Nodes. Administrators also use DDL or DCL statements to make changes to an Ocient System. When submitted to a SQL Node, the node executes the SQL statement across the system or forwards the SQL statement to the node assigned to execute it.Foundation Nodes
The Foundation Nodes store the user data in Ocient and perform the bulk of query processing. A key architectural concept of Ocient is the , which collocates data and processing where possible. The Foundation Node is the central element of this architectural principle. When a query is deployed to the Foundation Node, it performs as much of the query as it can with the data on the node before having to join, aggregate, or compare it to other data. It returns that result up to the SQL Node for further processing, packaging, and returning to the user. Foundation Nodes contain the majority of the storage in an Ocient System and are also typically the largest in number.Loader Nodes
Loader Nodes are responsible for extracting, transforming, indexing, and loading data ingested by Ocient from batch file sources as well as streaming data sources such as . A user can specify the extraction source details and supply a transformation pipeline that manipulates the structured or semi-structured source data before loading it into relational form into Ocient tables. Loader Nodes operate in a horizontal scale-out fashion allowing the loading system to scale to fit various ingestion requirements. Transparently to the end user, the Loader Node also manages exactly-once guarantees with data as it is loaded and converts pages into segments in the Foundation Nodes.Flows and Networking Between Nodes
Data and communication flows across the nodes of an Ocient System for a variety of different purposes. There are two networks that connect nodes, a 100 Gbps high speed network and a 10 Gbps network. These are used in different ways for data flows and administrative purposes.A Query in Ocient
When a user issues a query against the database, their SQL statement moves from the JDBC client to the SQL Node. The SQL Node parses and optimizes the query before handing the plan off to the Foundation Nodes. The Foundation Nodes do the first level of processing against the data before handing the results back to the SQL Node. The SQL Node further processes the data, constructs the results, and returns them to the client.- The connection between the SQL Nodes and Foundation Nodes is typically a 100 Gbps network connection. The speed of the connection between the client and the SQL Node is subject to the speed of that network (outside Ocient).
- Every Foundation Node is connected to every SQL Node.
Administration Flows
When administrators configure or make changes to an Ocient System, they do it using DDL and DCL using a SQL client. The SQL client relays the statement to a SQL Node, which parses it into commands that the Administrator Role on the SQL Node executes. This can impact the SQL Nodes, Foundation Nodes, or Loader Nodes, depending on the type of change or operation.- The administration flow connections with the Ocient System are 10 Gbps connections.
- Every node is connected to the SQL Nodes that perform the Administrator Role.
Loading Flow
When the load job is defined and started, the Loader Nodes read data from the source files, stage the data, process that data, and move the data into the Foundation Nodes. Data pipelines enable you to define the data load and any corresponding transformations to ensure data is properly loaded.- The network connections between the Loader and the Foundation Nodes are 100 Gbps.
- The Loader Nodes connect to every Foundation Node.
Database, Tables, and Views
Similar to other databases, an is a grouping of databases, schemas, tables, views, users, and data within one Ocient System. A single system can have multiple databases and schemas. Schemas define the structure of a database and contain the definition of tables, views, and indexes. While Ocient stores data on disk in columnar format, creating and working with tables in Ocient is like any other relational database. Ocient supports a wide variety of standard SQL data types along with an expanding set of geospatial data types. Read more about:- Data Definition Language (DDL) Statement Reference
- Data Query Language (DQL) Statement Reference
- Functions Overview
TimeKey and Clustering Key
Each table in Ocient can contain a column that is specified when defining the table. The TimeKey column is used to partition the data within the Foundation Nodes. Time partitioning is an important performance mechanism used by the OcientAIQ Unified Data Platform. Because many, if not most, queries specify some time filter for the results, time partitioning allows Ocient to quickly skip data from irrelevant times. When defining a table, users can also specify a clustering key containing one or more of the columns to further subdivide records on disk. This allows the database to quickly find records with the same key values. Read more in TimeKeys and Clustering Keys.Resilience to Hardware Failure
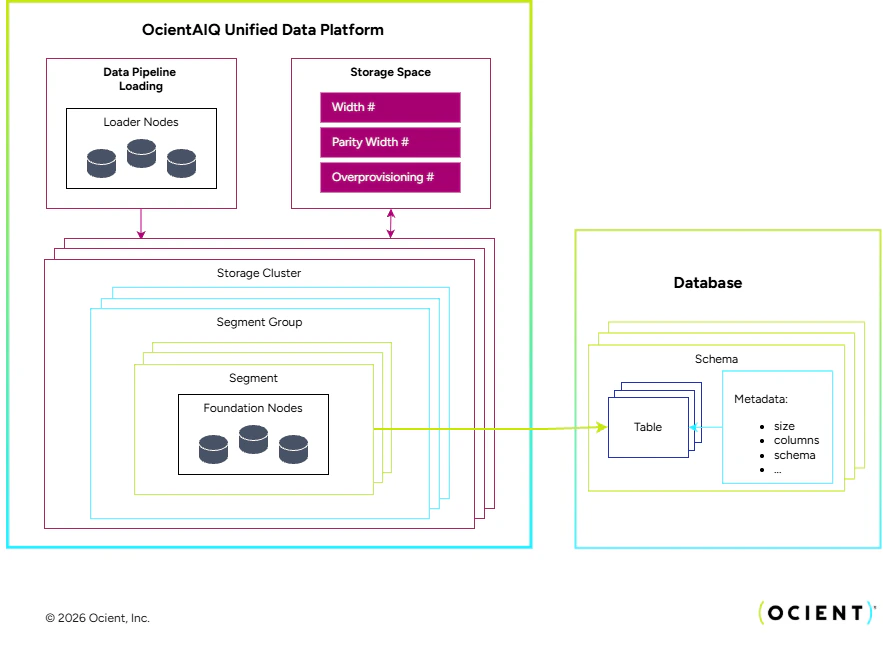
In order to provide reliability in the case of a hardware outage, Ocient uses erasure coding. Erasure coding is a mechanism to organize and compute parity blocks so that the system can rebuild missing data. This means that Ocient does not store redundant copies of the data for reliability. As a result, an Ocient System requires less overall storage than if it were storing one or more copies of the data for failover. When a user defines their storage configuration, they specify the width of the group and the parity width. These values can vary based on how many Foundation Nodes are in the system and how resilient users want to make the Ocient System.Segments and Segment Groups
Segments in Ocient are storage units that contain rows and are divided into a fixed number of coding blocks with a defined size. Segments are typically sized on the order of gigabytes. You set the segment size when you define tables in Ocient. The size of the segment must be a multiple of the coding block size. The coding block is the unit of parity calculation and the smallest unit of recovery as well. Multiple segments combine to form Segment Groups. A Segment Group has a fixed number of segments, named the width, which is the number of segments in the group. It also has a pre-defined number of parity blocks per set of data blocks for resiliency. Each segment has a defined index in the group. The Segment Group is physically stored in a storage cluster. Segment Groups can also be nested in directories named Segment Directory Groups. When the user configures an Ocient System, they need to define at least one storage space and a storage cluster. A storage cluster is a set of Foundation Nodes with an associated storage space. Also, these nodes coordinate together to store segment groups in a reliable manner. The storage cluster also has a width in the number of nodes. The width of the cluster and the Segment Groups stored on it must be the same. At the storage space level, the user defines the width and parity width of the space. Segments and their Segment Groups are stored across these storage spaces and clusters. To learn more about erasure coding, see Compute-Adjacent Input and Output on Large Working Sets. For details, see Configure Storage Spaces.