Specialized Indexes
The storage engine, execution engine, and optimizer are all aware of two special concepts that can bring about significant query performance benefits. Neither of these specializations are strictly required in any table or query, but the engine capitalizes on the fact that for the data sets with trillions or quadrillions of records they are often advantageous.Time Keys
Much of the data in hyperscale databases is produced by machines, devices, loggers, and sensors. The records these entities emit often have a temporal nature: they are timestamped or otherwise sequenced relative to each other. At query time, it is often the case that queries themselves have temporal predicates (e.g., “select all records for this user for this year”) as well. When these two conditions are met, the storage layer, execution engine, optimizer, and loading infrastructure all have special handling built-in for more efficiently processing these records. The time-based processing of records shares similarities with zone maps in that they can be used to avoid input and output (I/O) for non-intersecting sets of data when predicates against certain columns are present in a query. However, the specific temporal nature of the data is further utilized to make loading more efficient and also impacts segment grouping and data roll off.Clustering Keys
For many data sets, there is often a commonly queried set of columns that form the basis for a variety of analytical tasks. For example, in a network security database recording metadata of IP traffic, it might be the case that a substantial fraction of interesting queries are concerned with the public destination IP address, represented as a column in a record, in addition to other constraints or filters. When this is true for a subset of the columns in a given table, a clustering key can be defined, which enables additional specialized handling across the storage layer, execution engine, optimizer, and loading infrastructure. A clustering key shares some similarities with the “partitioning key” concept found in other databases in that it is defined in terms of one or more columns in the table and also factors into locality decisions for storage. However, unlike most systems, the clustering key is not a strict partitioning, and is instead only a ”hint” that promotes locality for storage to improve I/O efficiency for queries that locate records using it. Because it is only a (usually followed) hint, the storage layer and engine do not suffer from issues related to partitions outsizing others or forced locating of segments on particular nodes.Global Dictionary Compression
Global Dictionary Compression, or GDC, benefits both storage utilization and query throughput for columns with low cardinality (≤ ~1 million distinct values). When enabled for a specified column, that column’s values are mapped to a succinct global enumeration that is stored on disk and used at query time. GDC is often enabled for variable-length columns representing an enumerated set of potential values (e.g., city, county, and country names, or classification tags). In these scenarios, it provides significant compression and also enables a number of optimizations in query and join processing. In this latter category, the optimizer is able to delay or even eliminate the decompression step during execution because there exists a single global key-to-value mapping. This often results in a significant reduction in string data processing as well as network and memory bandwidth. Like other forms of compression, GDC is completely transparent to end users. New values are added to the global enumeration automatically, and compressed values are mapped back to their original value in query results.Specialized Types
Complex Types: Tuples, Arrays, matrices
In many analytical workloads, semi-structured and multi-dimensional data must be analyzed. Ocient offers complex data types to efficiently store and analyze this type of information, in many cases dramatically reducing query response times when compared to normalized schema designs. Each complex type allows groupings of elements to be stored and analyzed in a denormalized fashion with the parent record, and combinations of these complex types might also be used. This avoids the repetitive joins across billions of records required for nested data in a normalized schema improving query response times. Finally, Ocient’s indexing strategies extend to complex types as described here. The complex types supported in Ocient include Arrays, Matrices, and Tuples. An array is an ordered list of elements. The element can have any data type including a tuple. Array types provide operators for efficient set operations and standard SQL semantics like SOME and ALL. matrices are multi-dimensional arrays that share many of the same benefits as Arrays when denormalizing schemas or working with matrix data for mathematical operations. Tuples are structured objects in a single column created from individual data elements of the same or different underlying types. Arrays of Tuples provide the ability to denormalize structured elements that can then be jointly queried and indexed for improved performance in some cases. Because the array of elements can be stored in a columnar fashion and associated with the parent row, they need not be joined to the parent table repeatedly to query them. Performance is improved, and working set memory consumption is reduced on queries that would otherwise need to join tens of billions of rows to potentially trillions of rows. The flexibility of these composable complex types creates more options for database administrators to structure data and optimize performance at scale.Secondary Indexes
A variety of secondary index types are used to improve query performance. Secondary indexes are built and searched on a per-segment basis, allowing different segments of a specified table to be indexed differently where appropriate. For fixed-length column types, an I/O-optimized inverted secondary index enables fast equality and range queries. Variable-length columns support hash and N-gram indexes that enable fast equality andLIKE filters, respectively.
Complex types like tuples and matrices are a concise way to model certain data sets. In order to support efficient filtering on these types and their sub-components, filters are pushed into the I/O layer and use secondary indexes when possible.
You can create indexes on arrays of both fixed and variable-length elements to optimize contains, overlaps, and other similar operations. Additionally, for_all()/for_some() syntax allows other filters to be pushed down and applied to arrays using an index, without requiring unnest. In particular, for_all/for_some(varchar_array_col) LIKE <filter> utilizes N-gram indexes to optimize textual queries over arrays of strings.
Per-Segment I/O Pipelines
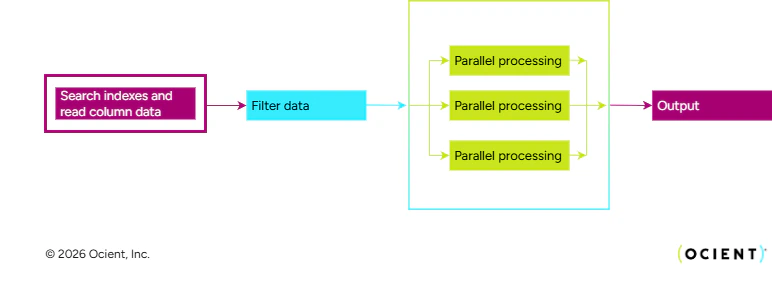
The I/O layer is designed to minimize the amount of on-disk data read and processed for each query by compiling a custom I/O pipeline for each segment of data the query accesses. An I/O pipeline is a directed acyclic graph that represents an efficient I/O plan for the particular columns and filters of that query combined with indexes and data that can vary from segment to segment. This plan adjusts for data demographic changes over time, and for schema or index changes also. Just like the query plan itself, efficient pipelines are critical for performance. A simple I/O pipeline example is illustrated here: This graphic example shows the I/O process stages that go into action when the Ocient System compiles a pipeline. These stages are as follows:- When a query is in the IO pipeline, each segment first searches indexes to minimize the data that must be read and processed.
- The indexes help to quickly filter the rows. When possible, filter predicates are pushed down and evaluated in-line, further reducing the number of rows needed to read, even when an appropriate index does not exist.
- The system reads rows that pass the filters in parallel.
- The system returns the query output.
Optimizing I/O with Bloom Filter and Index-Based Join Push-Down
A pair of advanced techniques are employed to dynamically reduce the amount of I/O needed when processing certain types of joins.- Index-based join push-down — As a running query narrows the collection of potentially matching values, an updated list of filters can be dynamically pushed down into running I/O pipelines. When a matching index is present, the I/O layer can begin using it mid-query to reduce I/O. Otherwise, this technique has the same benefits of early filtering as a pushed-down Bloom filter.
- Bloom filter push-down — When one side of a join is fully determined, the execution engine can build a Bloom filter that gets pushed down into running I/O pipelines to enable early filtering of unneeded values at the lowest level. As a probabilistic data structure, Bloom filters can be tuned to provide filtering benefits for even high-cardinality sets.
Query Execution
Parallelism
The storage layer and I/O access patterns to promote parallelism would be of limited impact if the data processing working on the actual data was not itself highly parallel. To that end, the execution engine (which is named the Virtual Machine or VM) is designed to maintain parallel and disjoint flow of data during data processing. A query plan is a (mostly) directed graph of plan operators in a tree-like arrangement. At the leaves of the tree are the raw I/O operations undertaken to bring records off of SSDs and into memory for processing. Internally, iterative processing, computation, filtering, and joining is undertaken by successive operators to produce the final results for the query. The execution engine is named the VM because it structures plan operators as assembly instructions (such as ADD andMOV) to be scheduled and executed.
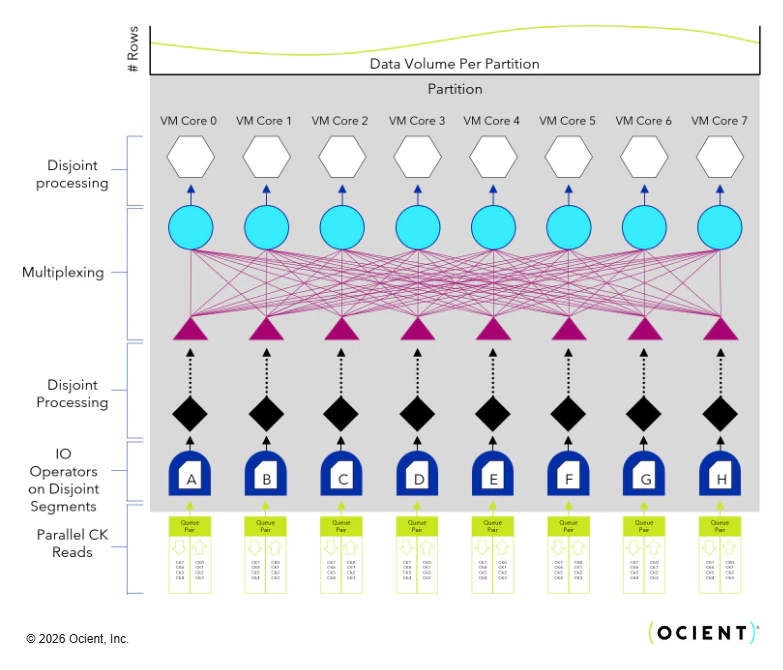
The fundamental organizational unit of this execution engine follows a design pattern named resource-aligned parallelism where a series of independent execution units, strongly coupled with hardware resources like cores, memory, and disks, disjointly process independent data partitions of records that flow independently and in parallel within the engine. Because minimal to no data sharing is required across data partitions, the execution engine not only maximizes resource utilization and throughput, but also scales very well as CPUs continue to include larger numbers of cores.
The number of data partitions across any edge within the plan tree is usually, but not always, equal to the number of distinct VM cores. Each VM core is a dedicated and isolated CPU core that does not process any other database or system threads (this is achieved using a kernel feature named “cpu isolation”). Then, each plan operator is locally “compiled” into a number of operator instances that is equal to the local number of VM cores. In this way, any individual operation within a plan can be spread over all allocated computational units to independently process the parallel disjoint subsets of records it is to handle.
Of particular note is the attention paid to data skew. In order to maximize aggregate throughput across all parallel operator instances, it is required that they perform approximately the same amount of work. If work is not evenly distributed across all parallel processors, then query execution is limited to the slowest one while the others have no work. Even partitioning of data is easy to achieve in some cases, and impossible in others (it depends on the operation and the data), but the Ocient engine undertakes a variety of special efforts to evenly balance data flow, even in non-trivial cases.
S0, S1, S2, ..., Sn where for all n, the integers in Sn are all less than the integers in Sn+1. Then, one could sort each subset, in parallel, to end up with a totally ordered sequence of integers across all sub-sequences. Put another way, the system splits and groups the integers at boundary values on the number line, then sorts each interval independently. The problem of data skew arises when the number of rows per interval (or subset) is not roughly equivalent, with the worst case being where one interval has all the integers and the others all have none. The problem is one of boundary selection: any naive choice can be subject to skew. To address this in the sort case, the database engine, in conjunction with information provided by the optimizer based on metadata and statistics, adjusts the boundaries for the ranges such that each boundary has a roughly equivalent number of rows.
Implementation Efficiency
When discussing parallelism, you might have noticed several terms that sound very operating-system-like: threads, disjoint cores, compilation, and so on. In fact, the database engine directly implements many general pieces of functionality that are usually in the domain of the operating system, but with database-specific features that outperform standard system-provided ones.- Specialized hugepage-backed memory allocators. Designed for high throughput and low lock contention, these allocators are backed by hugepage memory, not only deriving the benefits of fewer TLB misses, but also making them suitable for userspace I/O operations because their virtual to physical address mapping is fixed. Special efforts were made to make them extremely fast and efficient within the resource-aligned parallelism pattern.
- Cooperative per-VM-core Scheduler. This component runs per VM core, allocating CPU time to operator instances on that core to process data. In this framing, each operator instance can be considered as a parallel thread on its core. However, the scheduler is not a generic thread scheduler, but instead has access and visibility into inter-operator data flow, concurrent query memory utilization, and workload management limits. This means that it has a much richer set of information with which to make intelligent scheduling decisions that promote maximal total system throughput.
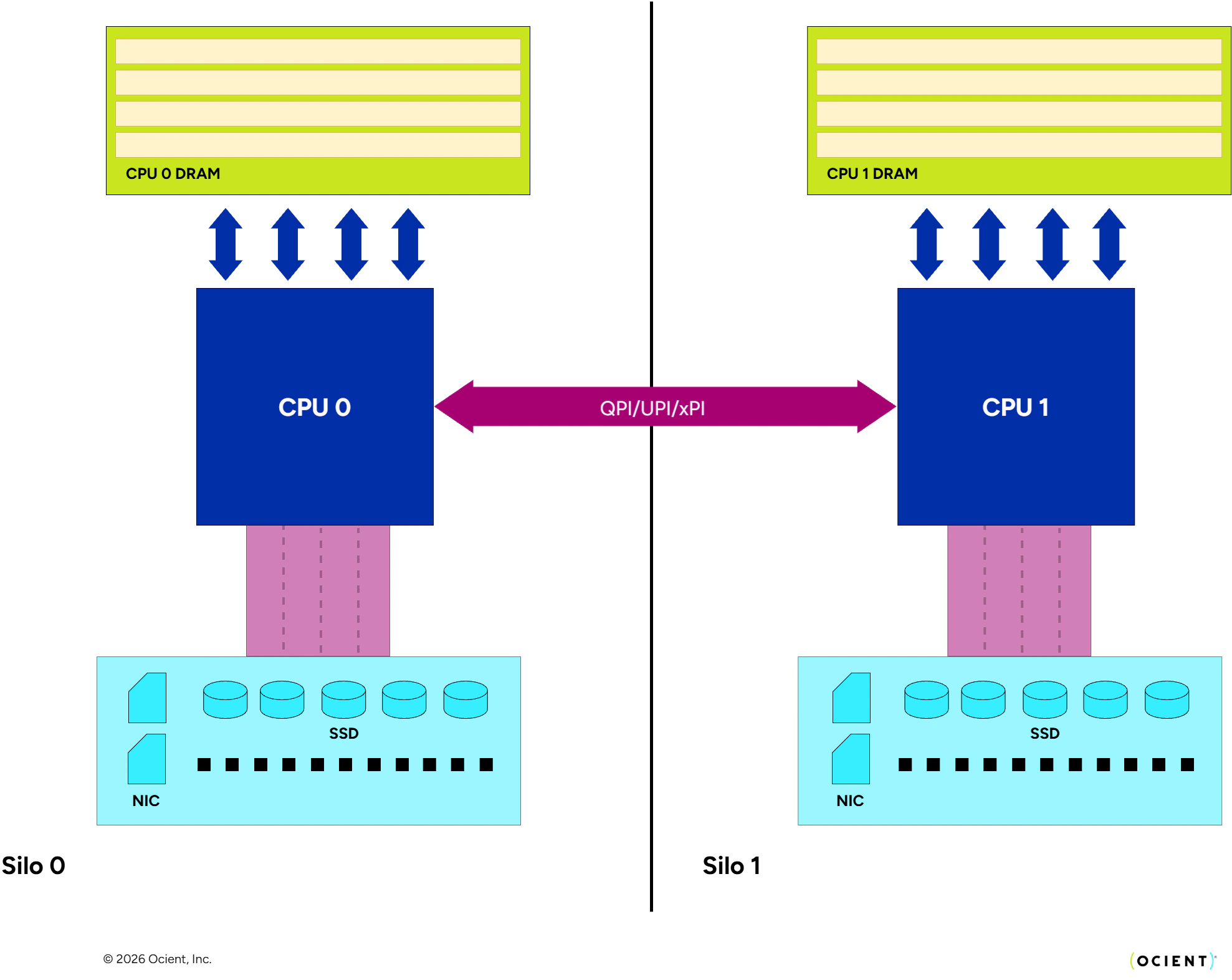
- NUMA-aware Data Processing. Modern multi-socket systems utilize a non-uniform memory architecture (NUMA), whereby individual CPUs (and the cores in them) have both local memory and remote memory. The implication of this is that a particular memory access made against local memory by code executing on a core is not only lower latency than a remote one, but also avoids an expensive hop across a dedicated memory bus with a finite amount of bandwidth. Because most commodity CPU packages directly integrate a PCIe bus as well, it is the case that not only is there local and remote memory, but local and remote devices as well. To account for this, the VM groups locally-connected RAM, disks, and cores into a functional unit named a silo that for all practical purposes is treated as an isolated and independent processing unit. Generally speaking, records for a particular disk will be read only into local memory, and only processed on local cores, all within that silo. This avoids expensive cross-socket communication and greatly improves throughput.
Related Links
Secondary Indexes Understanding Data TypesRelated Videos
At the Whiteboard with Ocient: SQL at ScaleLinux® is the registered trademark of Linus Torvalds in the U.S. and other countries.