Data Pipelines Overview
A data pipeline is the primary way that the System loads data. Each data pipeline is a database object that defines the end-to-end processing of data for the extraction, transformation, and load into Ocient tables. Data pipelines execute across your Ocient System to coordinate parallel loading tasks across many Loader Nodes and pipelines.The Pipeline Object
Creating a pipeline is complex as there are many options to consider. Use thePREVIEW PIPELINE SQL statement to preview the pipeline creation and load of data to ensure that the pipeline definition returns the results you expect. After you are satisfied with the results, you can execute the CREATE PIPELINE statement to create the pipeline at scale. For details, see the CREATE PIPELINE SQL statement.
When you create a pipeline, you assign it a name and the pipeline exists as an object in the Ocient System connected to this name. Then, you can control the object using your chosen name with SQL statements like START PIPELINE, STOP PIPELINE, CREATE OR REPLACE PIPELINE, and DROP PIPELINE. You can also define your own function by using the CREATE PIPELINE FUNCTION SQL statement. Execute these statements using a SQL connection.
A pipeline maintains its own position during a load and enforces deduplication logic to ensure that the Ocient System only loads data once. The lifecycle of a pipeline defines both the deduplication logic and load position.
- Pipeline Events: During the life of a pipeline, you can start, stop, modify, and resume the pipeline without duplicating source data or losing the position in a load.
- Pipeline Updates: You can modify pipelines using the
CREATE OR REPLACESQL statement to update the transforms in a pipeline, but maintain the current position in the load. - Load Position: If target tables are truncated or if a target table is dropped and then recreated, the pipeline maintains its own position in the load and continues from its last position.
Parts of a Pipeline
Pipelines can operate in either aBATCH or CONTINUOUS mode based on how you plan to load your data. Or, for transactional batch loads, you can use the TRANSACTIONAL mode with the optional START FOREGROUND clause.
The DDL for Data Pipelines has three sections.
Thus, for example, the full SQL syntax has this format for the
orders_pipeline data pipeline. This syntax has an S3 data source and loads data into the orders table in the public schema. The SELECT SQL statement in the CREATE PIPELINE statement selects the id, user_id, product_id, and other columns from a table.
SQL
Data Source
TheSOURCE part in a pipeline defines the source of the data to load. This DDL part identifies the type of the source (e.g., S3, ) as well as the details for the data that is relevant to the source (e.g., S3 bucket and filters, Kafka topic and consumer configuration).
Data Format
TheEXTRACT part in a pipeline defines the format of the data that the Ocient System extracts from the data source. This part includes the data format (e.g., delimited, binary, JSON) and the details about the records (e.g., record delimiter, how to treat empty data). In addition, the Ocient System extracts metadata that you can load into tables.
- Loading Delimited and CSV Data
- Loading JSON Data
- Load Parquet Data
- Loading Binary Data
- Loading Metadata Values
- EXTRACT Options Reference
Transformations
TheINTO table SELECT ... SQL statement defines the target tables where the data loads and uses a SELECT SQL statement to extract fields from the source data (e.g., CSV field index $5, JSON selector $order.user_name) and map them to target columns (e.g., ... as my_column).
The SELECT statement in a pipeline can utilize a subset of SQL functions to convert the extracted data into the required format during loading (e.g., TO_TIMESTAMP($my_date, 'YYYY-MM-DD')).
The selectors you use to extract data from the source records can differ based on the data format (e.g.,
JSON or DELIMITED).- Data Pipeline Load of CSV Data from S3
- Data Pipeline Load of JSON Data from Kafka
- Data Pipeline Load of Parquet Data from S3
Pipeline Lifecycle
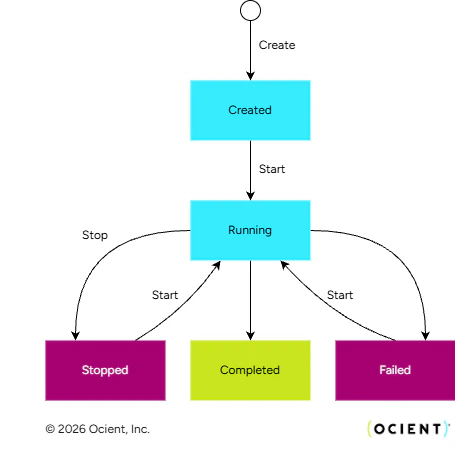
This state machine shows the state transitions for a data pipeline. You can start and stop data pipelines using DDL statements. The status of the pipeline transitions automatically as the pipeline completes all assigned work or reaches a failed state. While executing, the pipeline lists files or connects to streaming sources and creates tasks to execute work. These states reflect the overall progress of a pipeline and capture details of the underlying tasks that execute the work of the pipeline.
In this state diagram, the transition arrows display the user actions that can trigger a state change. State transitions without a label are system-initiated transitions.
Observe Pipelines
During pipeline operation, all of the information you need to observe progress, pipeline status, key events, success or failure, and errors is available in system catalog tables in the Ocient System. In addition, performance counters are available for many key loading metrics that you can add to observability systems.Troubleshooting Pipelines
Data pipelines support robust error-handling capabilities crucial for developing new pipelines, identifying issues with ongoing operations, and correcting bad data. Pipelines can include a bad data target where the Ocient System saves bad data for troubleshooting. In addition, the system captures errors that you encounter during loading in system catalog tables such assys.pipeline_events and sys.pipeline_errors. Exploring the data in these tables enables you to detect issues and identify the root cause of errors during loading.
- Manage Errors in Data Pipelines
- Frequently Asked Questions for Data Pipelines
- Data Pipeline Loading Errors
- Bad Data Targets Reference
- Error Handling Options Reference
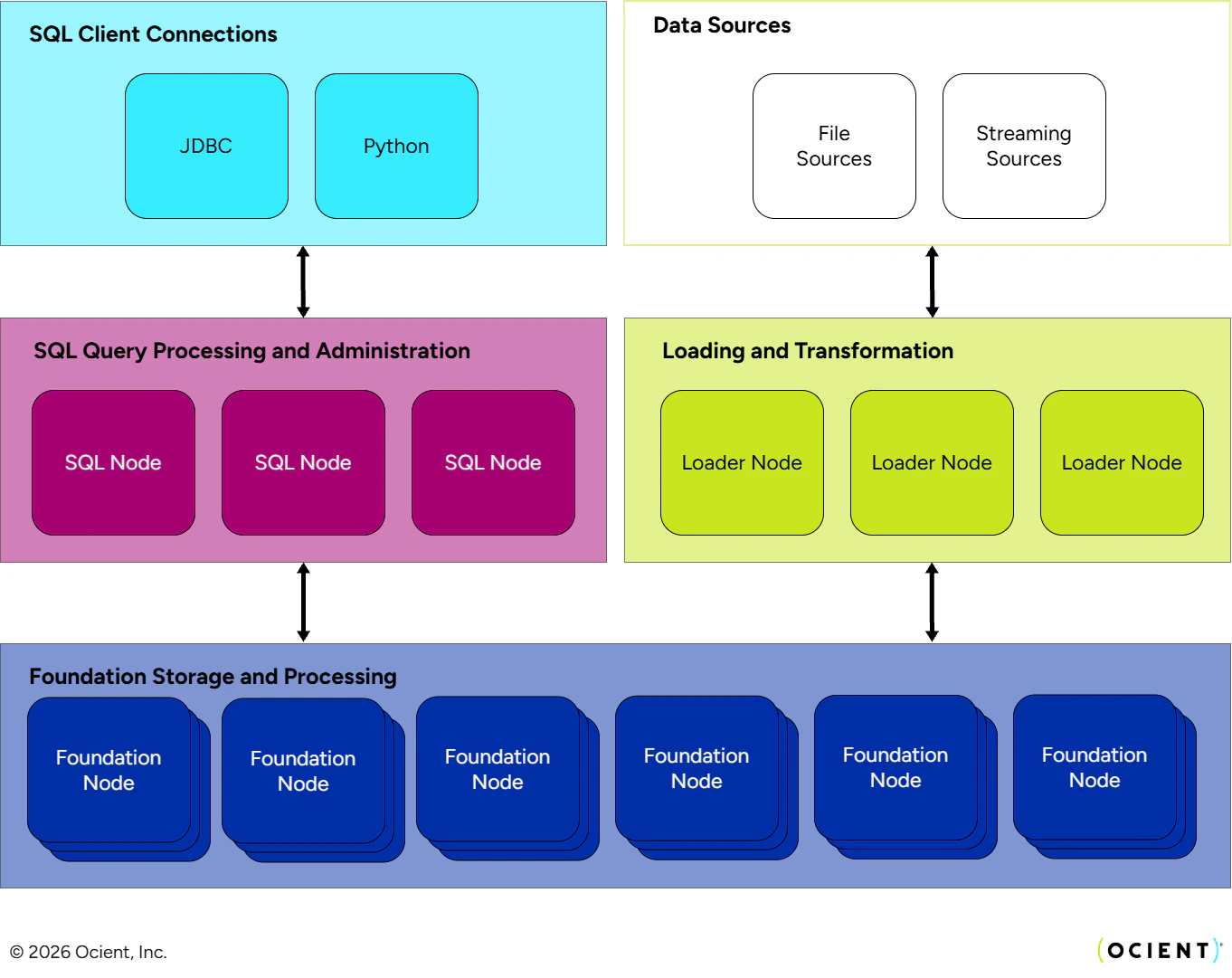
Loading Architecture
Pipelines require Loader Nodes to operate. Loader Nodes are Ocient Nodes that have thestreamloader role assignment. The loading system can use all active nodes with this role to process pipelines.
When you execute a pipeline, Ocient spreads the work among the available Loader Nodes. The system executes these parallel processes as tasks on each of the Loader Nodes. Then, the system partitions the files or Kafka partitions to load across the tasks, and loading proceeds in parallel. When all tasks are completed, the pipeline is completed. Many pipelines can run in parallel on the Loader Nodes, and these Nodes share resources.
The scale-out architecture of the Ocient System allows you to add more Loader Nodes as needed to expand the volume and complexity of pipelines that you can operate at the throughput required by your application.