Record-Level Resolution
The distinction between “stream” and “batch” is somewhat arbitrary, depending on the system in consideration, but in the loading infrastructure the fundamental unit of loading is a single record in a table. Put another way, the various guarantees listed here are made on a record-by-record basis and not on batches of records. Supporting this is the concept of a record stream of which the loading infrastructure can manage an unbounded number. A record stream is an ordered sequence of records, and loading considers each record in a stream independently of each other.Low Latency Querying
A key design goal of the loading system was a low time to query-ability or TTQ. Strict guarantees are not made but this usually means that any record presented to the loading system is available to be queried on the order of seconds. An interesting property of the implementation is that the variance on TTQ decreases as the aggregate record rate increases. This is because the loading system maintains internal structures named pages that accumulate records, and the faster they fill the more quickly they are made available for querying.Low Latency Durability
A necessary requirement of low-latency querying is the ability to ensure that any particular record is stored in a fault-tolerant manner. To guarantee correctness of query results it must be the case that when a record is considered during query execution (either included or filtered out) it must be considered for all subsequent queries until it is deleted by the user. The durability guarantee made by the loading system must come before query-ability (and therefore is measured in seconds on a record-by-record basis) and matches the system’s configured fault tolerance. For example, if the erasure coding scheme in use has aK value of 2, then the loading system must store all records in a manner that allows for at least 2 losses before they can be made queryable.
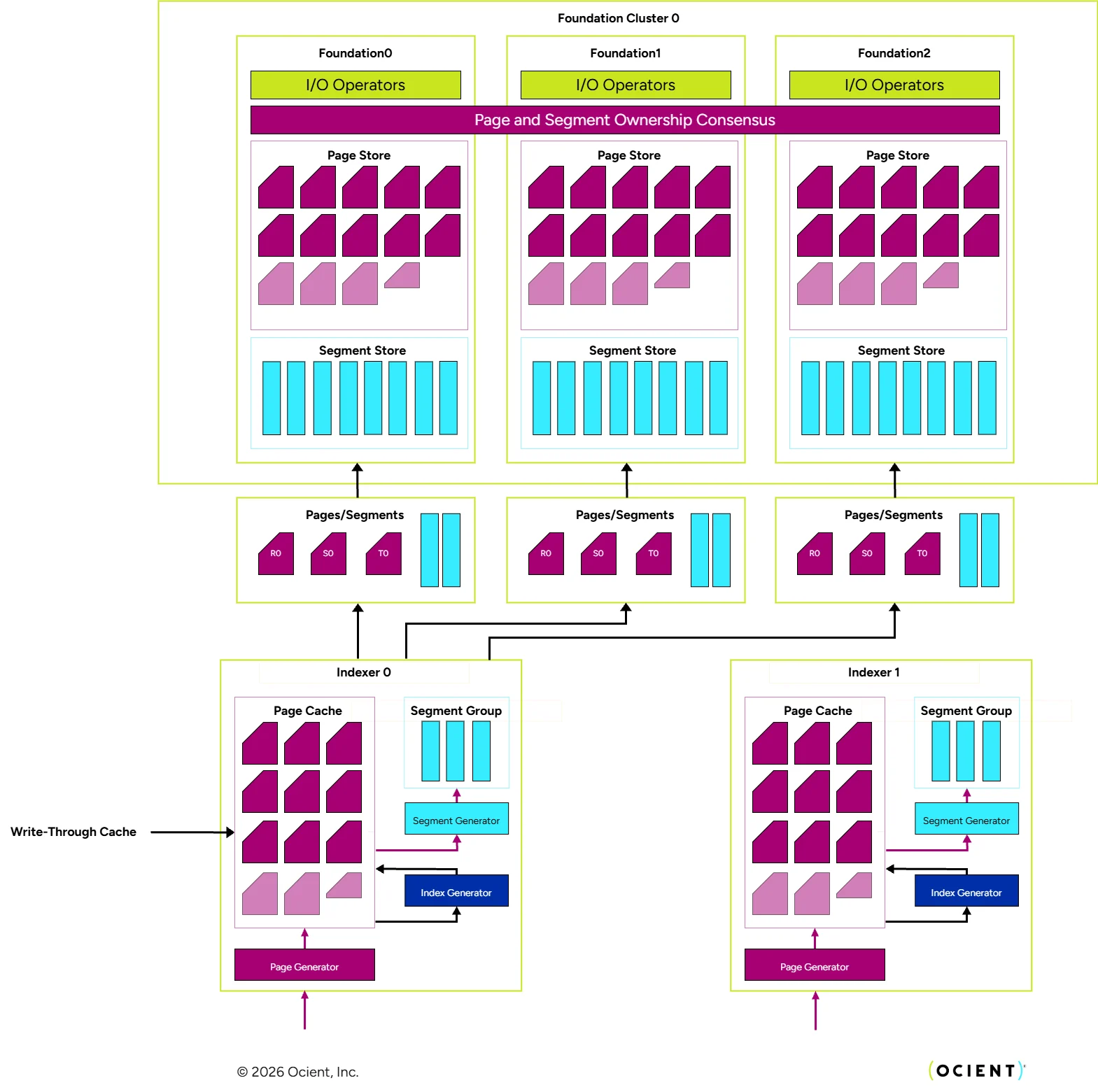
The unit of durability in the loading system is named a page and within the loading and storage system, a page shares many characteristics with the segments: each page is a self-contained set of records and their own local metadata and statistics, and the consensus-based ownership scheme mediated by the storage clusters is the same for both. However, there are some key distinctions:
- Typical Size — A page is usually substantially smaller than a segment. While segments can be multiple gigabytes in size, pages are more commonly around 100 megabytes.
- Replication — Segments are grouped together into segment groups and mutually erasure coded for fault tolerance. Pages, however, are replicated within the storage layer. This is less space efficient for the same fault tolerance, but pages are short-lived: they exist only long enough to be converted into segments, which are denser and richer in metadata. Because they do not exist for very long, the extra storage overhead of the replication scheme is inconsequential, and the loading system opts not to waste the computational effort computing the erasure-coded parity data.
Exactly-Once Guarantee
When the record stream sources can support it, the Ocient loading infrastructure is capable of providing exactly-once semantics for every record loaded. This means that the record source and the query layer can be guaranteed that every record presented for load is not only not lost (no “gaps” exist) but also not duplicated. On the surface, this seems like an obvious and simple requirement, but at millions of records per second in a fault-tolerant distributed system, it is extremely non-trivial to provide this guarantee. The loading systems of other database engines can also provide this guarantee, but often with caveats that might not be acceptable. For example, executing a sequence ofINSERT INTO statements within the context of a transaction is a possible approach, but distributed transaction processing does not easily scale to millions of records per second. Beyond that, there is the issue of how to manage inter-transaction guarantees that place additional requirements on the data sources.
If transactions are not in use, it is generally not possible to provide exactly-once guarantees without a bi-directional contract executed by the record source and the loading system. In a very common form of this contract, the loading system provides the exactly-once guarantee by guaranteeing it will de-duplicate any records presented more than once (i.e., the loading system is idempotent with respect to record insertions). Then, the source can safely re-send any records the loading system does not indicate it has received. So long as the source resends anything it has not been explicitly told was received (and made durable) the two endpoints can together guarantee every record will be present exactly one time.
When this approach is taken, the loading system’s job becomes simple deduplication. On some systems, this is achieved using unique record identifiers. First, the source must be able to indicate a column or set of columns whose values taken together for any particular record uniquely identify it. Then, for each record inserted, a hash set or other structure is consulted. If the unique identifier is not present, it is inserted, if it is, the record is silently dropped. While technically cheap to implement, this scheme suffers because the set structure cannot be allowed to grow indefinitely, and therefore some time or size based bound is placed on the exactly-once guarantee. An additional significant issue is that it is challenging and expensive to ensure the set structure is replicated or distributed amongst all nodes participating in the loading system. This presents correctness and scalability challenges to the exactly-once guarantee.
The Ocient loading system takes the idempotent deduplication approach, but performs its deduplication checks in a different manner. The crux of the scheme is that most systems that aim for exactly-once guarantees are also able to replay their record streams in the same order. This is true for queuing systems such as as well as file sources such as files stored in S3. Due to this property, the Ocient deduplication scheme tracks a durability horizon for each distinct record stream. Recall that a record stream is an ordered sequence of records. The durability horizon is an ever-advancing offset into a stream that indicates the record at which the data warehouse guarantees all previous records up to and including that record, for that stream, are guaranteed durable. Using this scheme, the source can easily identify the set of records it should send or re-send. In the loading system, deduplication becomes cheap in both time and space: the system need only store the durability horizon per stream (instead of an unbounded set), and deduplication checks are as simple as a basic interval check comparing whether or not sequences of records stored in pages overlap.