Loading and Transformation (LAT) Overview
This section provides an overview of how loading works in Ocient along with step-by-step examples to illustrate the key aspects of the loading process. A separate LAT Reference provides a detailed explanation of the options for each data format and data source in Ocient. The key elements in the Loading system are:- Data Source — an origin source for data such as S3, , or . Sources can be file or streaming in nature.
- Data Type Extraction — the format for data extraction from the source. Examples include JSON, CSV, fixed width.
- Transformations — the functions used to cleanse, route, and transform the incoming data.
- Indexer — operated by the
streamloaderrole on a Loader Node, the Indexer collects transformed records, stores in replicated pages, and converts into segments on the Foundation Nodes.
- LAT Data Types in Loading
- LAT Pipeline Configuration
- LAT Client Command Line Interface
- LAT Metrics
- LAT Advanced Topics
- LAT Packaging and Installation
Loading Overview
The LAT is a service within an Ocient System that is responsible for fetching data from file or streaming sources, extracting records, transforming them, and routing them to Ocient tables. The LAT runs as a standalone process on Loader Nodes. It runs many parallel workers on high-core count servers to deliver the required parallelism for high-throughput loading. This diagram shows that a set of Loader Nodes sit between the data sources and the Foundation Nodes to control the loading flow and deliver high performance across many parallel workers.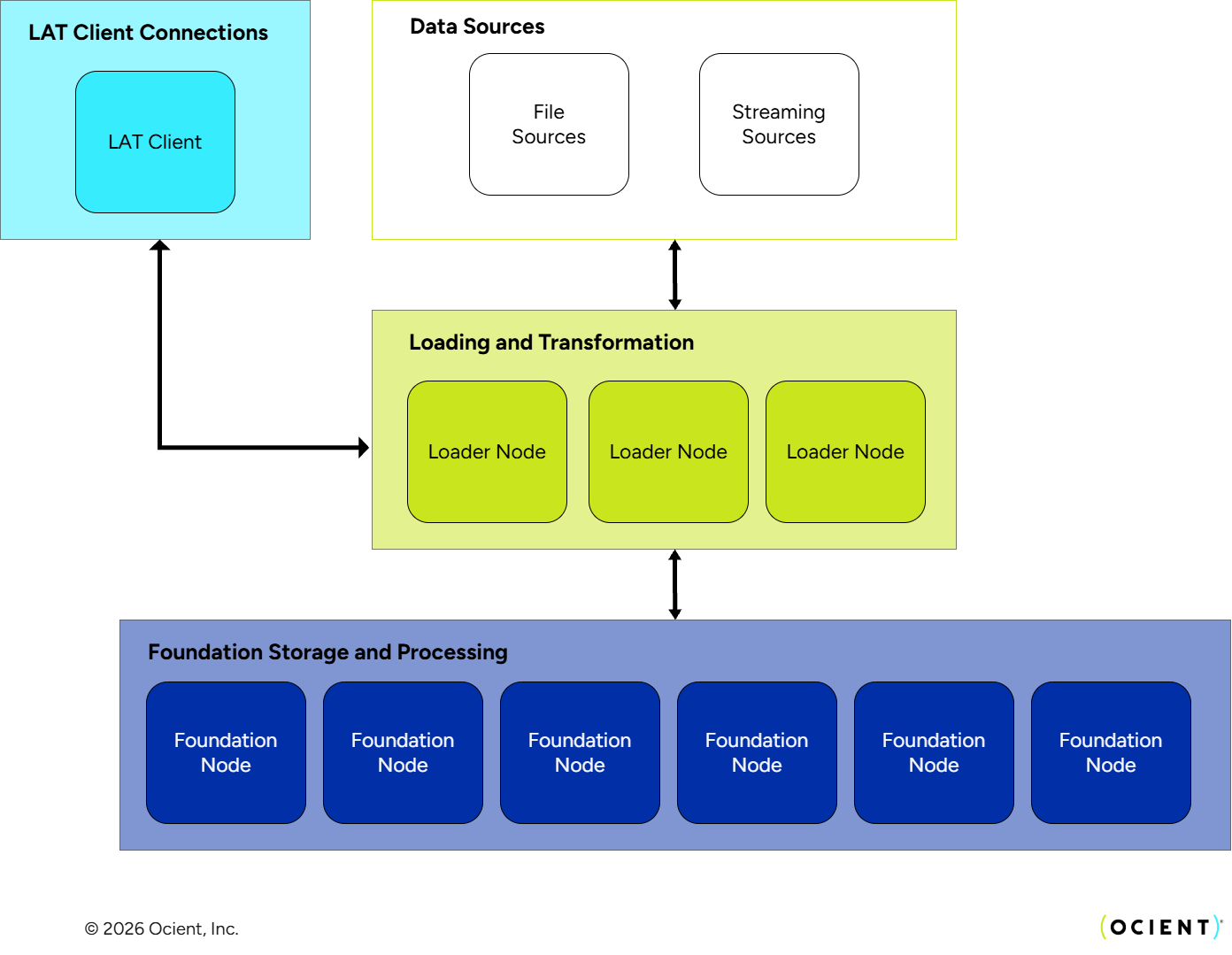
- Streaming Sources — continuous loading of data from an ordered stream such as Kafka
- File Sources — a discrete batch of data loaded from files until complete, typically from a file system or object storage solution like AWS S3
Pipelines Overview
The process and configuration that defines how data is loaded is referred to as a “pipeline.” A “pipeline” defines the end-to-end data flow in a loading task including the Source type (e.g., Kafka), the record Extraction for the data type (e.g., CSV extraction), the transformations on each record (e.g., JSON value extraction, data exploding, string concatenation, flattening), and where transformed data should be loaded in Ocient tables. As shown in this diagram, a user sets each of these sections in the pipeline file to control the LAT.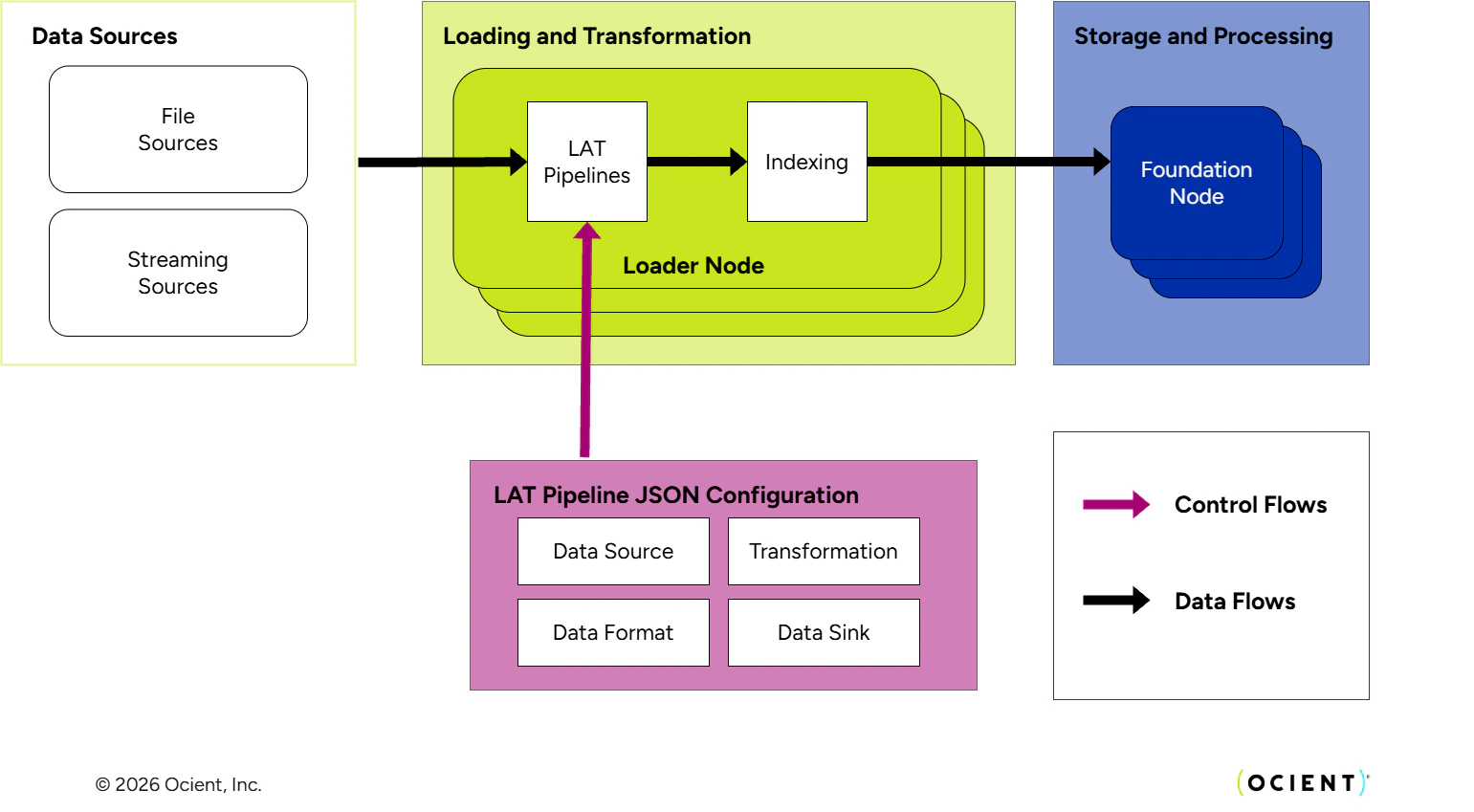
Time Ordering
The Ocient System contains timeseries data. Loading in the data warehouse is considerably faster when data is presented in an ordered time sequence according to the TimeKey in a table. For most streaming sources, this is typically accomplished automatically with limited “out of order” data by the nature of the queue. However, for file based sources, it is not uncommon for data to be collected in folders in a manner that could appear haphazard to the loader. For this reason, it is critical that thesort_type setting for file based sources be used correctly to inform the LAT how files should be ordered.
Read more about file sorting in Load From a File Source.
Exactly-Once Guarantees
Loading in Ocient is designed to ensure exactly once processing of data. The LAT operates independent streams of data that each has a monotonically increasing row ID tied to an individual row in a File-based load or a partition offset in a Kafka-based load. Exactly-once processing is made possible through coordination between the loading components around a “Durability Horizon” that represents the highest record durably stored on non-volatile storage in each independent stream. In the event of a node outage or a replay of the data, the Durability Horizon automatically removes duplicate records in an efficient manner. It is important to understand how the LAT determines the unique row ID for different source types to ensure that data is loaded correctly. This is described in more detail in the LAT Reference Documentation. Learn more about the underlying approach used in Loading Characteristics and Concepts.Dynamic Schema Changes
Ocient also supports schema changes on tables while loading data in a continuously streaming pipeline. Ocient maintains a table version with each running pipeline that serves as a loading contract until the load task complete. This ensures that existing pipelines are not interrupted when columns are added or removed from a table that is receiving new data. Ocient continues loading records using the original table version even after a change has been made to the tables. These dynamic schema changes fromALTER TABLE commands allow flexible updates to tables while complex loading processes are active. Pipelines can then be updated to add or remove data elements and match the altered schema, reducing the burden of coordination across systems.
Loading Examples
The following examples walk through a simple loading example using the LAT for a streaming load off of Kafka and a file load off of S3. These examples are very similar due to the way the LAT uses a common language for all transformation and loading regardless of data source or data type. The final set of examples outline some more complex transformations. Examples:- LAT Load JSON Data from Kafka
- LAT Load CSV Data from S3
- LAT Load JSON Data from S3
- LAT Advanced Loading and Transformations